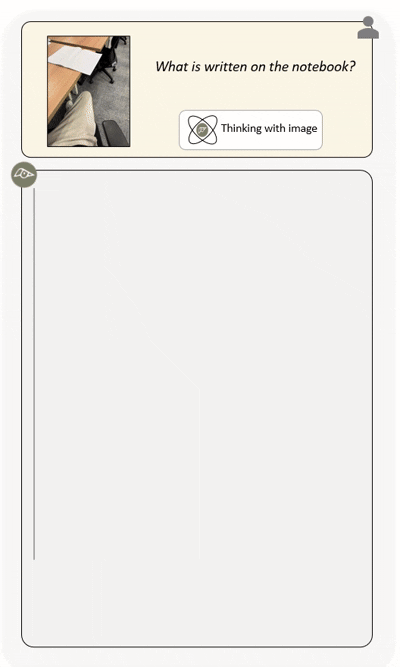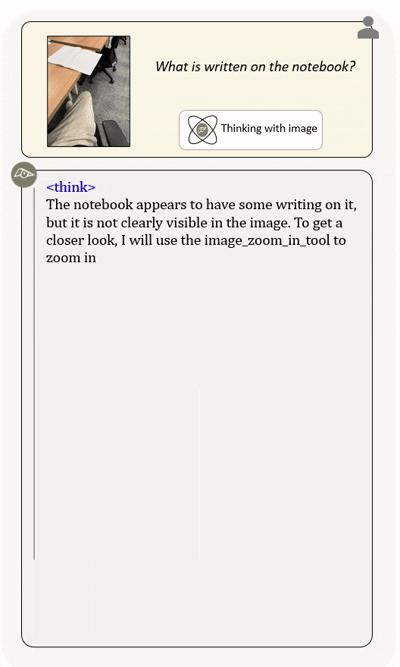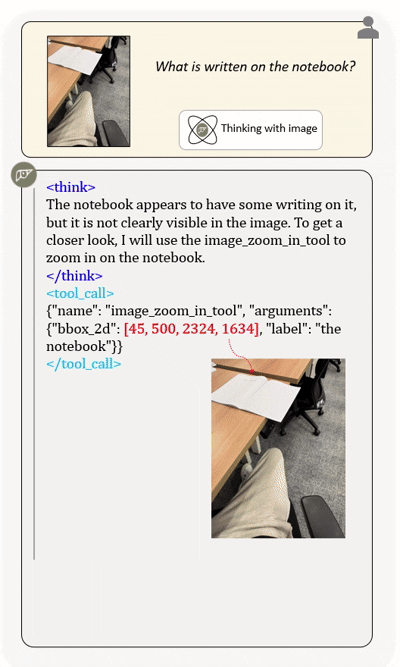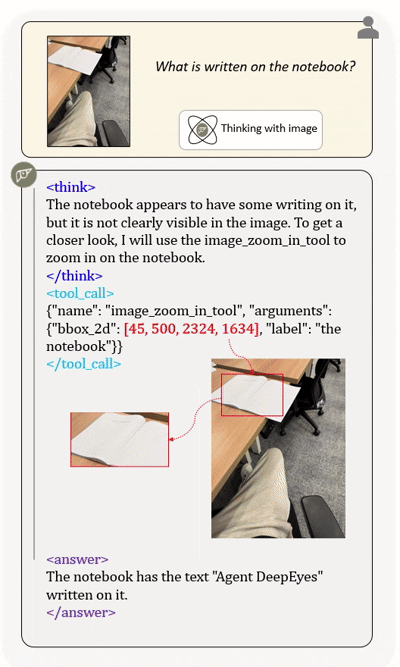

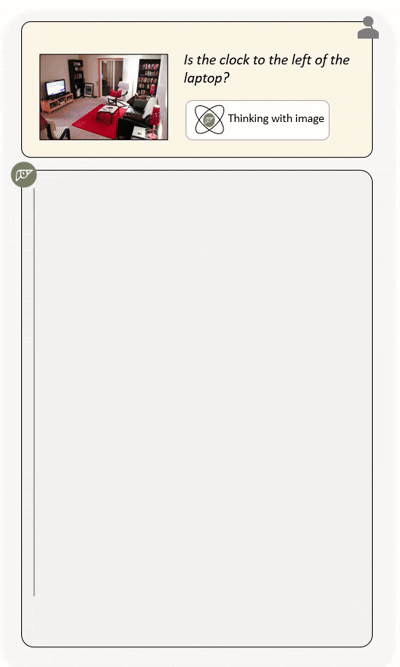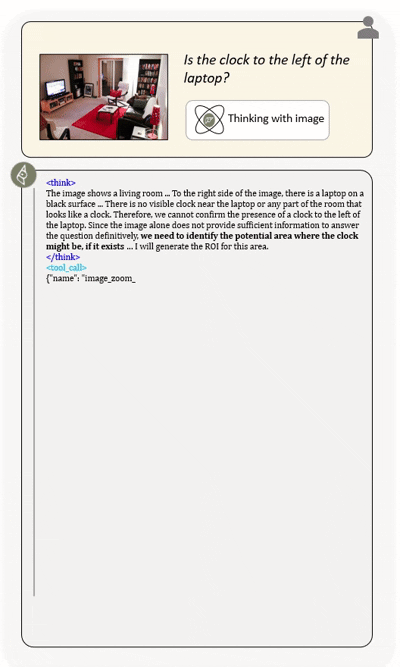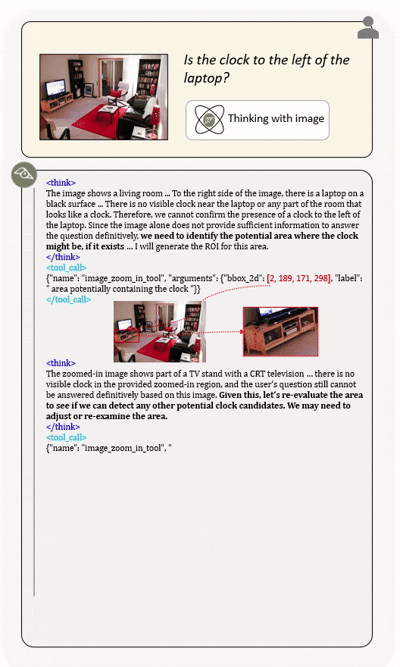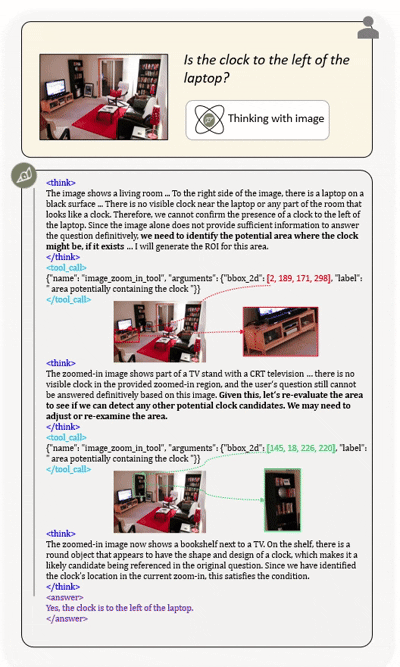
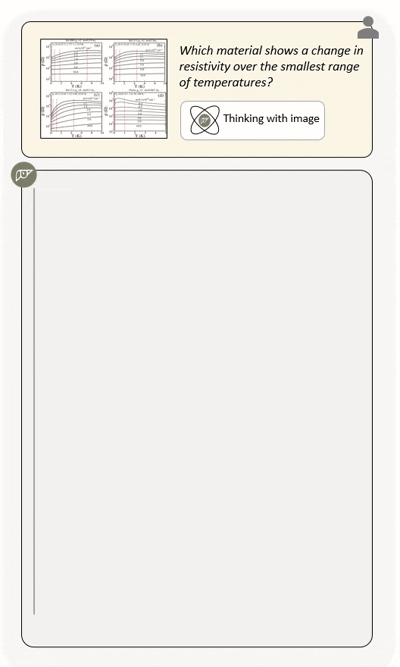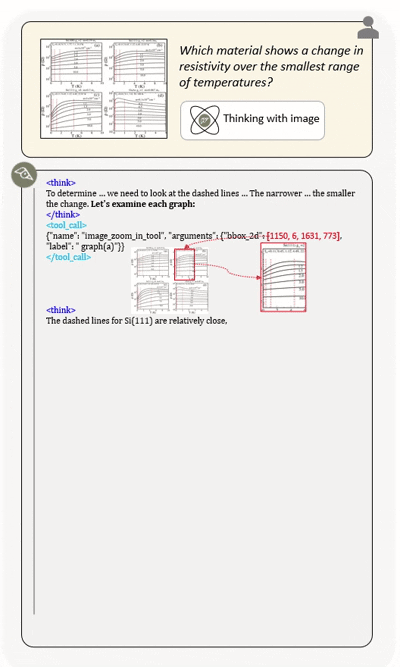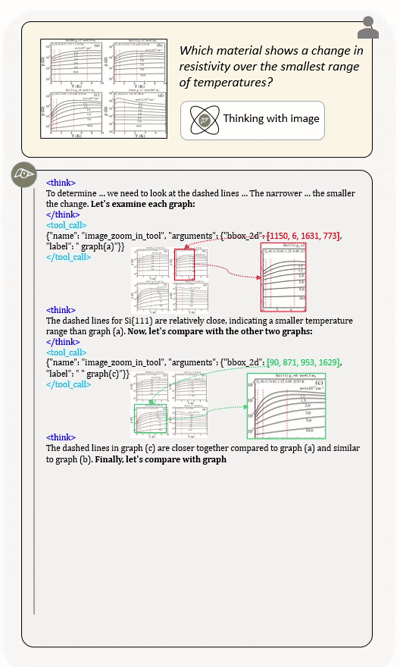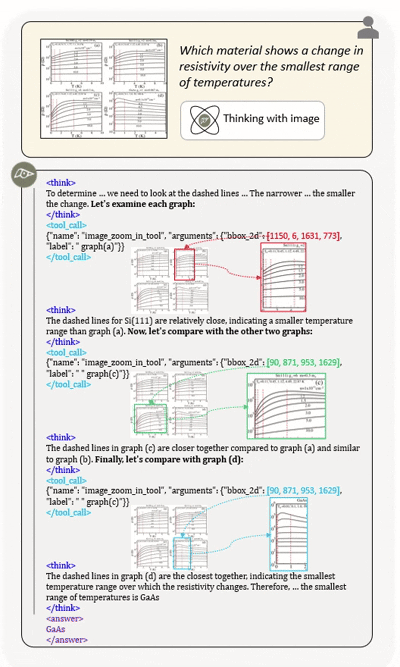
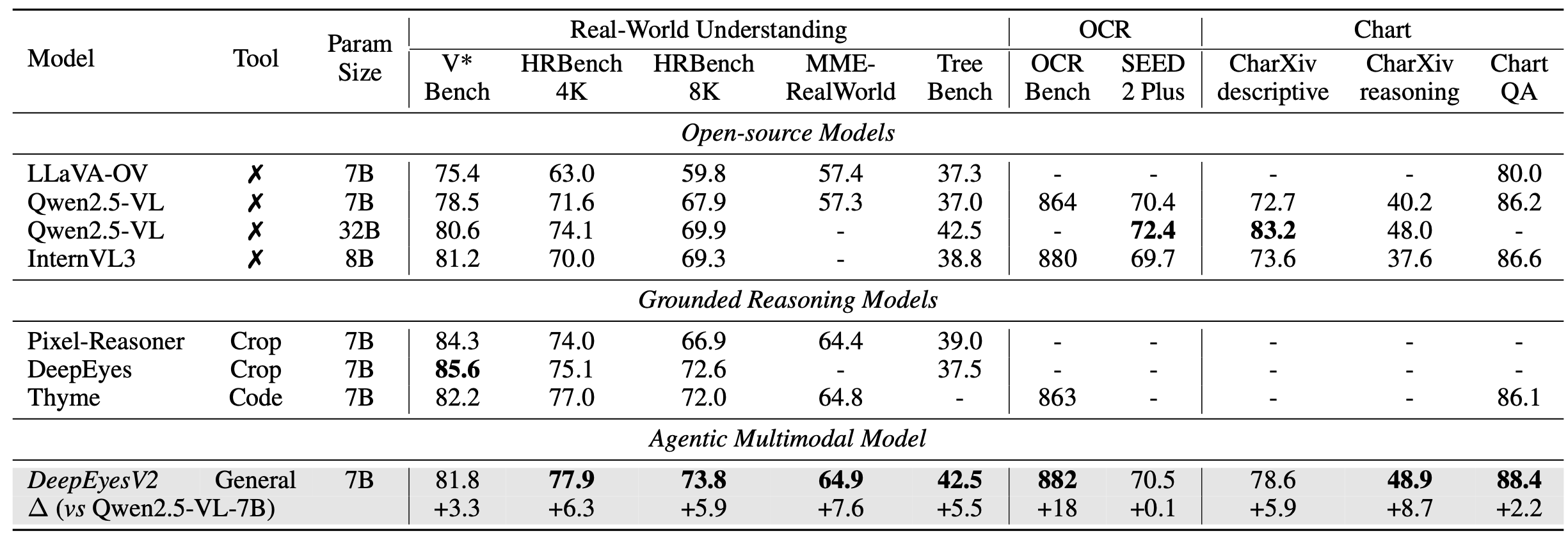
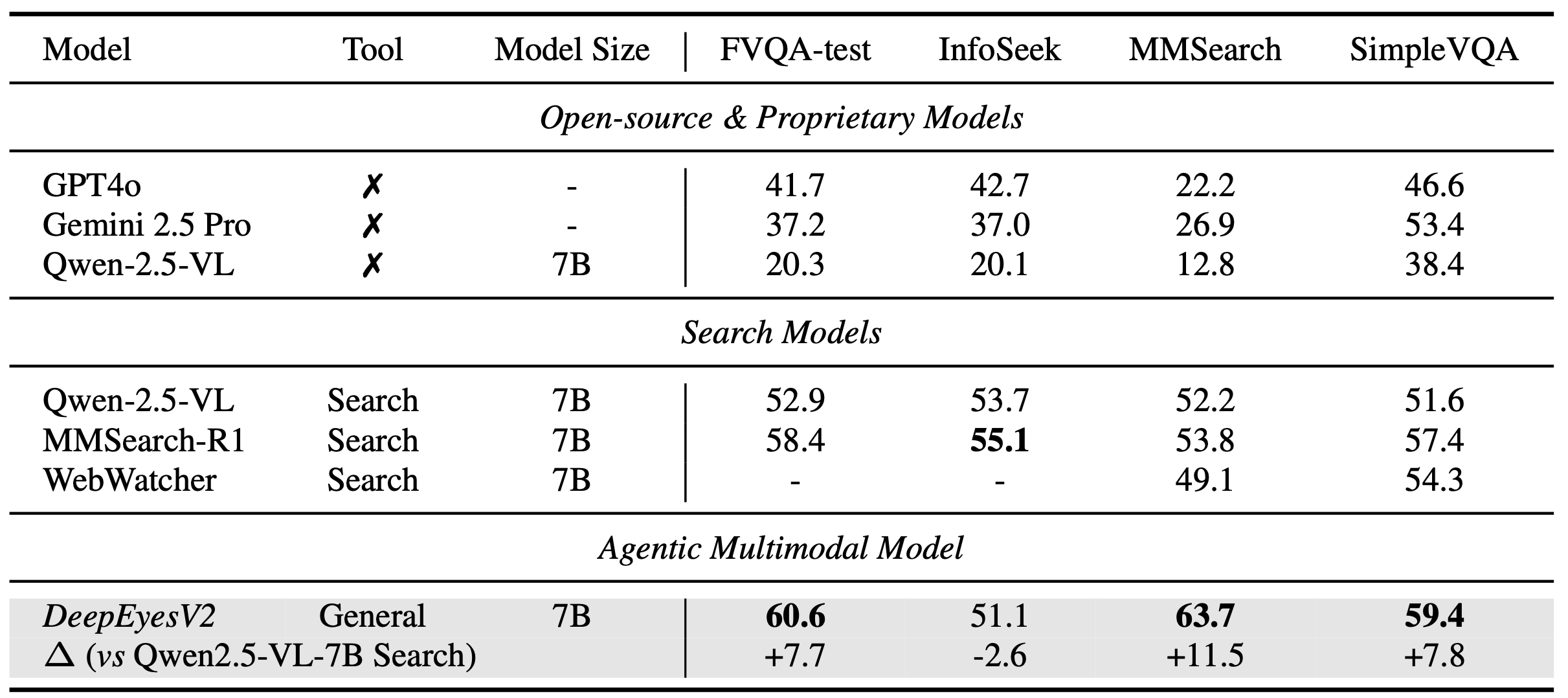
Agentic multimodal models should not only comprehend text and images, but also actively invoke external tools, such as code execution environments and web search, and integrate these operations into reasoning. In this work, we introduce DeepEyesV2 and explore how to build an agentic multimodal model from the perspectives of data construction, training methods, and model evaluation.
We observe that direct reinforcement learning alone fails to induce robust tool-use behavior. This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation. We curate a diverse, moderately challenging training dataset, specifically including examples where tool use is beneficial. We validate DeepEyesV2 across real-world understanding, mathematical reasoning, and search-intensive benchmarks, demonstrating that systematic tool integration enables reliable and extensible multimodal reasoning behaviour. Moreover, DeepEyesV2 exhibits task-adaptive tool invocation, tending to use image operations for perception tasks and numerical computations for reasoning tasks. Reinforcement learning further enable complex tool combinations and allowing model to selectively invoke tools based on problem context. We hope our study can provide guidance for community in developing agentic multimodal models.
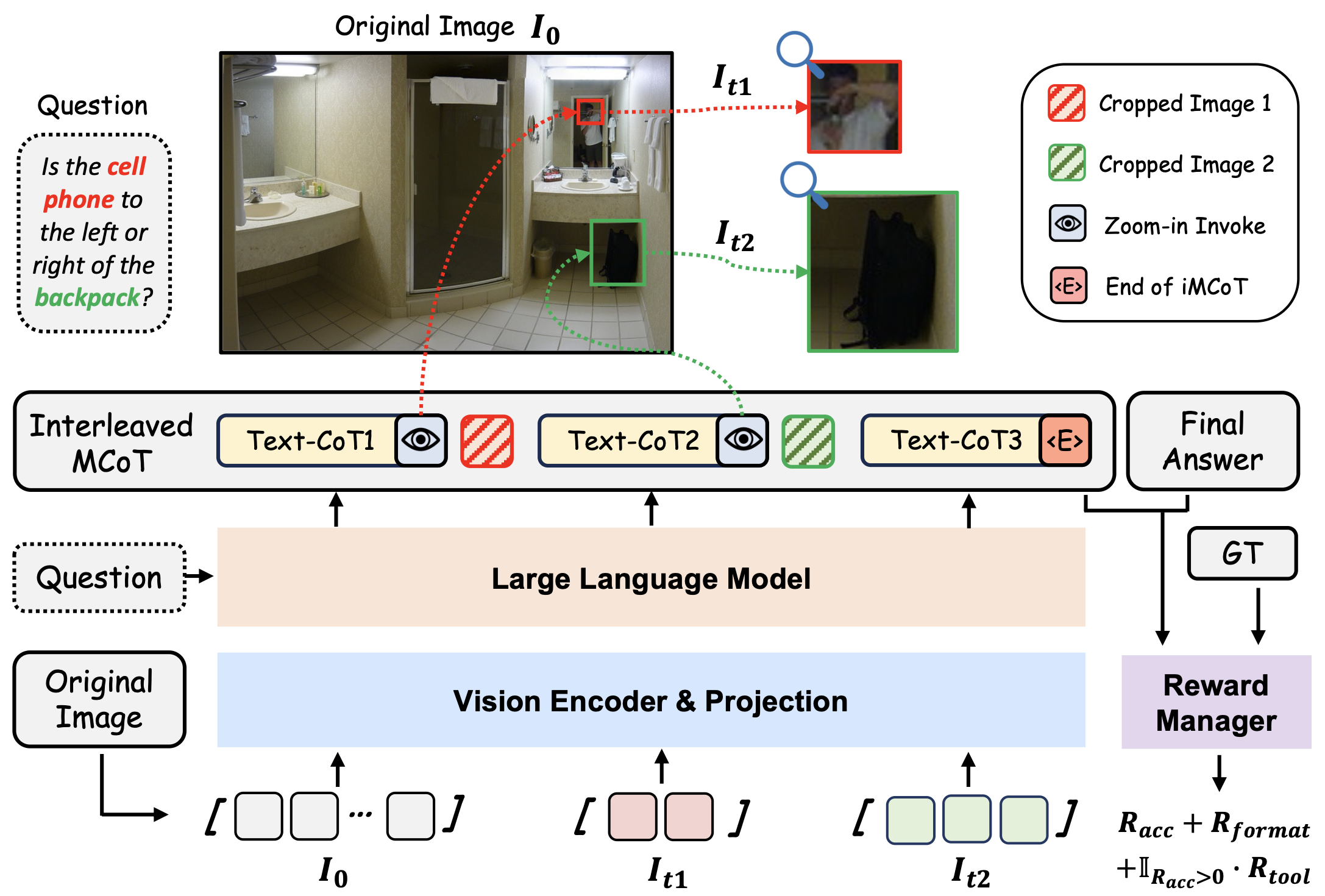
Pipeline of DeepEyesV2
DeepEyesV2 invokes tools and incorporates execution results into subsequent reasoning steps,
enabling iterative and tool-augmented multimodal inference.
Similar to DeepEyes, DeepEyesV2 is an agentic multimodal model, but with extended tool-use capabilities beyond simple cropping. In DeepEyesV2, programmatic code execution and web retrieval are treated as complementary and interleavable tools inside a single reasoning trajectory. Given an image input and the corresponding user query, DeepEyesV2 first generates an initial reasoning plan, and explicitly determines whether this question can be solved directly through internal reasoning or requires tool invocation. If tool use is necessary, DeepEyesV2 emits executable Python code or issues web search queries. All tool outputs are converted into observations and appended to model's context. DeepEyesV2 then thinks further in light of these observations and may plan further tool invocations (either additional code, further searches, or both), iterating this reasoning-tooling-integration loop until a conclusive answer is produced.
DeepEyesV2 can dynamically choose, combine, and use tools as reasoning unfolds. This integration yields three main advantages: (i) it allows expanded and enhanced analytical capability through executable code; (ii) it enables active and real-time knowledge seeking by retrieving multimodal evidence from the web; and (iii) it supports iterative, interleaved multi-tool reasoning, in which code execution and search can be dynamically combined within a single trajectory, rather than being isolated modules. Together, these features position DeepEyesV2 as a more general, reliable, and extensible framework for multimodal reasoning.
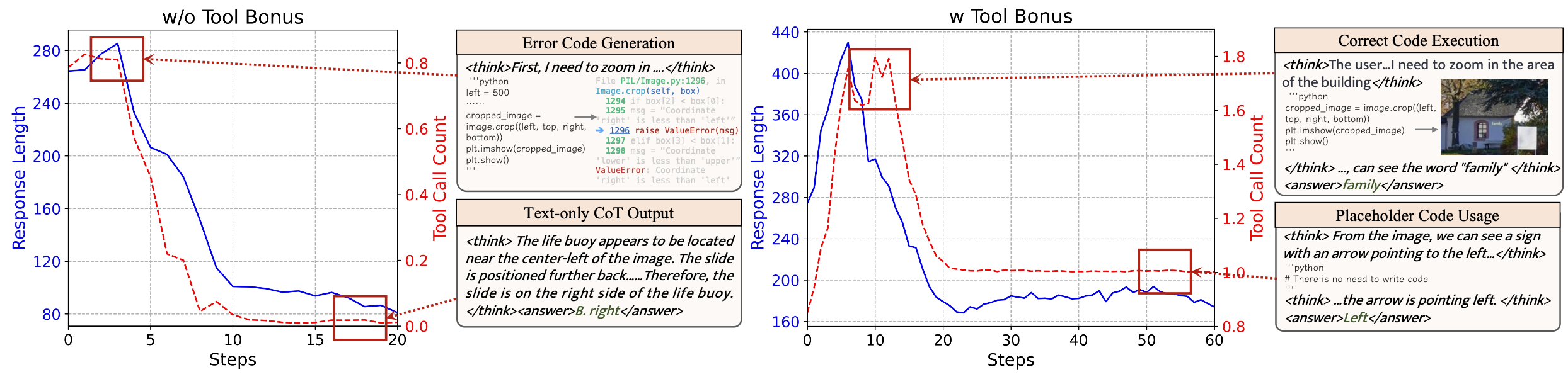
To investigate whether MLLMs can directly acquire tool-use ability through reinforcement learning, we first conduct a pioneer experiment on Qwen2.5-VL following DeepEyes. During training, we observe two kind of trends:
(1) Naive RL. In the early stage, model occasionally attempts to produce Python code, but these outputs are often buggy or fail to execute, casionally attempts to produce Python code, indicating that existing MLLMs struggle to generate stable and reliable code. As training contin- ues, model gradually abandons code generation and converges to producing only short reasoning chains followed by direct answers, thereby bypassing tool use. (2) Incorporating tool usage bonus. Then, to encourage tool invocation, we incorporate the tool usage bonus mechanism from DeepEyes, which explicitly rewards the generation of code. With this additional signal, model is indeed able to produce correct and runnable code in the early stages, suggesting that the mechanism can enforce coding ability. However, with continued training a new degeneration emerges: model's behavior converged to emitting exactly one code block per query, and this single block typically consists of non-executable, placeholder comments rather than meaningful code, revealing the phenomenon of reward hacking. This pioneer experiment highlights that existing MLLMs cannot reliably learn complex tool use through direct RL alone, motivating the need for a cold start to bootstrap model's tool invocation ability.Following DeepEyes, we collect data in accordance with the following principles:
(i) Diverse tasks and image distribution. We incorporate varied data to cover a wide range of multimodal challenges and visual components. (ii) Verifiabilityand structured format. All questions are reformulated into a structured, open-ended QA format to facilitate objective evaluation. We exclude examples that cannot be reliably verified, such as those with incorrect answers, ambiguous phrasing, or poor readability. (iii) Appreciate difficulty. We exclude examples that the base model can easily solve and prioritize questions that remain challenging. (iv) Beneficial integration of tools. We categorize examples based on whether tool usage leads to correct answers. Cases where model can solve correctly using additional tool calls are reserved for reinforcement learning, whereas examples that remain unsolved even with tool assistance are used for cold start.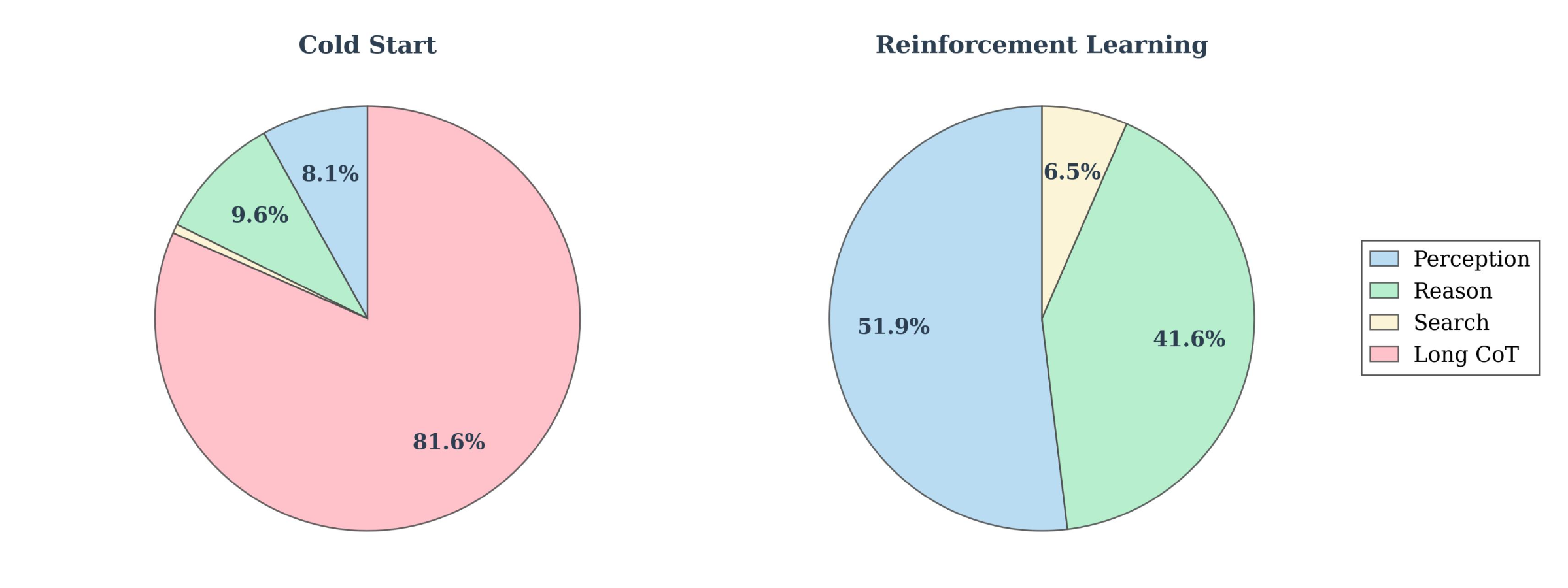
Distribution of cold start and reinforcement learning data.

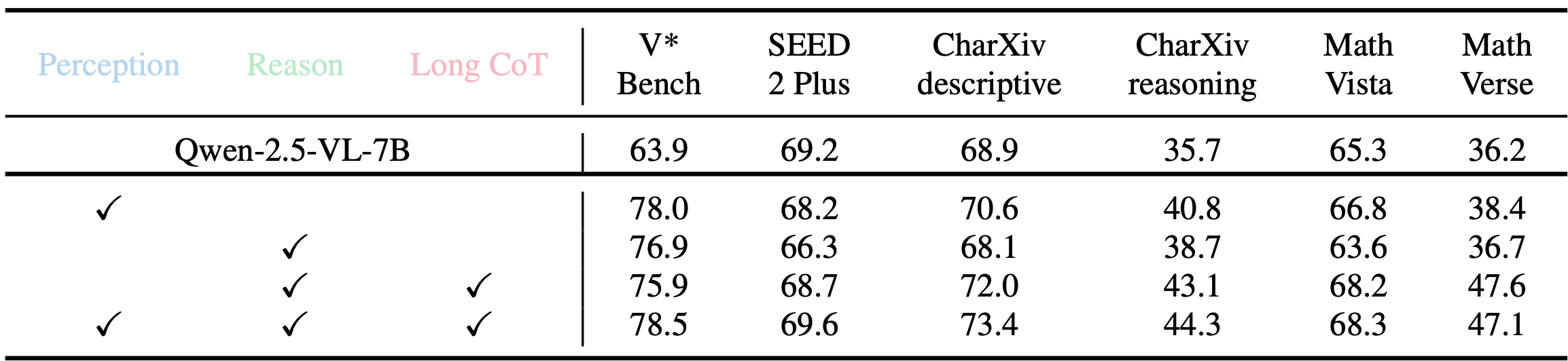
Ablation study on cold start data
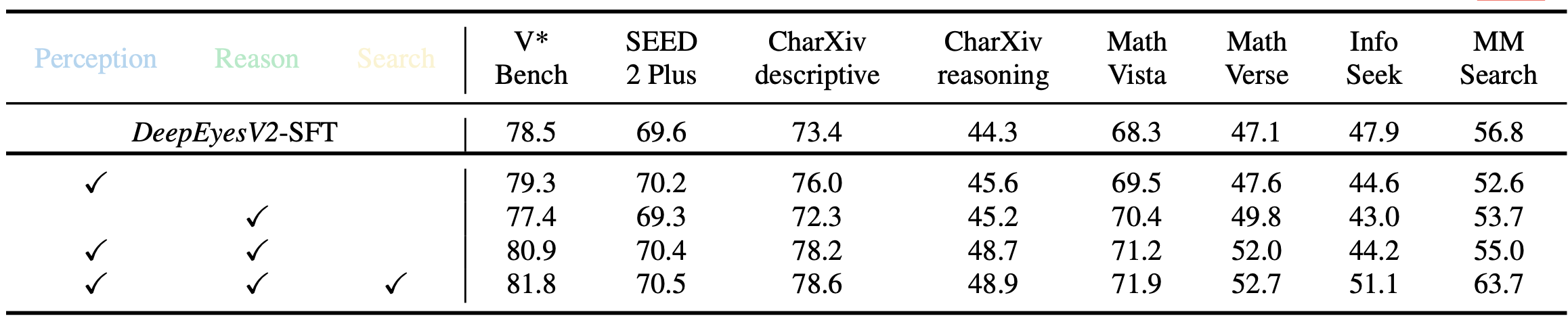
Ablation study on reinforcement learning data
Diverse training data is important for improving model generalization. Besides, the introduction of long CoT cold start data can strengthens reasoning and substantially improves tool use on complex tasks.
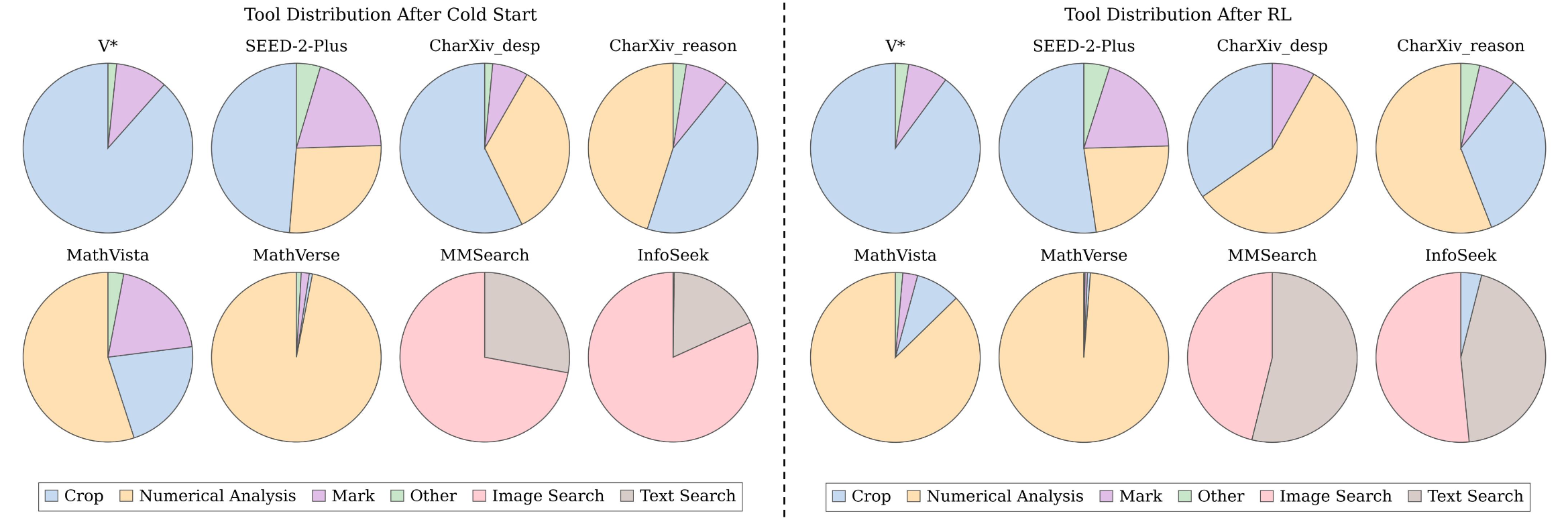
Tool distribution comparison
Model exhibits different distributions of tool call across various tasks. Additionally, after reinforcement learning, model tends to perform more numerical analysis.
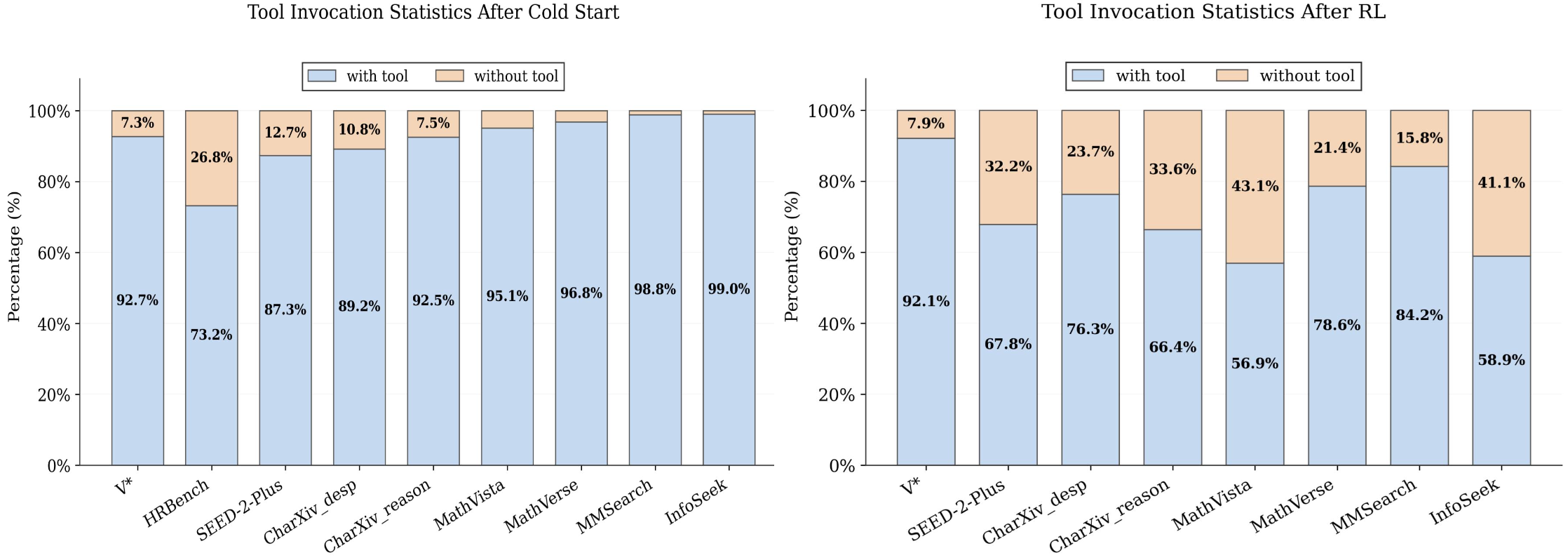
Tool invocation statics
Reinforcement learning can effectively improve the efficiency of tool invocation. After reinforcement learning, model's tool invocation rate significantly decreases, indicating that model learns adaptive reasoning. When tool calls are not necessary, model directly solves problems instead of invoking ineffective tools.
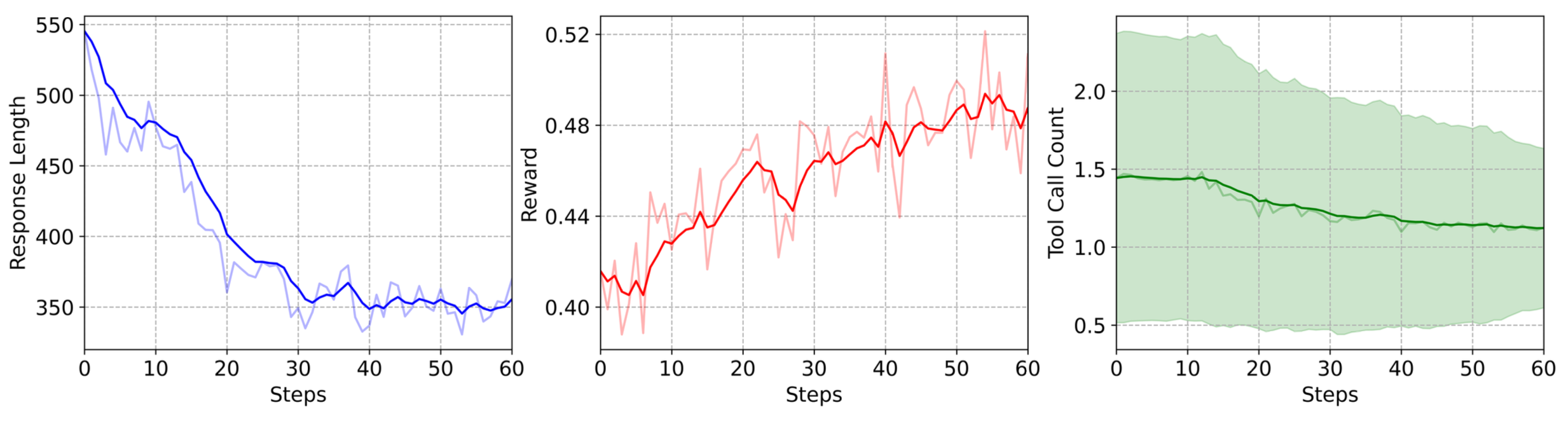
Training dynamics of RL
# DeepEyesV2
@article{hong2025deepeyesv2,
title={DeepEyesV2: Toward Agentic Multimodal Model},
author={Hong, Jack and Zhao, Chenxiao and Zhu, ChengLin and Lu, Weiheng and Xu, Guohai and Yu, Xing},
journal={arXiv preprint arXiv:2511.05271},
year={2025}
}
# DeepEyes
@article{zheng2025deepeyes,
title={DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning},
author={Zheng, Ziwei and Yang, Michael and Hong, Jack and Zhao, Chenxiao and Xu, Guohai and Yang, Le and Shen, Chao and Yu, Xing},
journal={arXiv preprint arXiv:2505.14362},
year={2025}
}